VISTA: Enhancing Visual Conditioning via Track-Following Preference Optimization in VLAs
Abstract
Vision–Language–Action (VLA) models have demonstrated strong performance across a wide range of robotic manipulation tasks. Despite the success, extending large pretrained Vision-Language Models (VLMs) to the action space can induce vision-action misalignment, where action predictions exhibit weak dependence on the current visual state, leading to unreliable action outputs. In this work, we study VLA models through the lens of visual conditioning and empirically show that successful rollouts consistently exhibit stronger visual dependence than failed ones. Motivated by this observation, we propose a training framework that explicitly strengthens visual conditioning in VLA models. Our approach first aligns action prediction with visual input via preference optimization on a track-following surrogate task, and then transfers the enhanced alignment to instruction-following task through latent-space distillation during supervised finetuning. Without introducing architectural modifications or additional data collection, our method improves both visual conditioning and task performance for discrete OpenVLA, and further yields consistent gains when extended to the continuous OpenVLA-OFT setting.
Visual Conditioning Study and Results
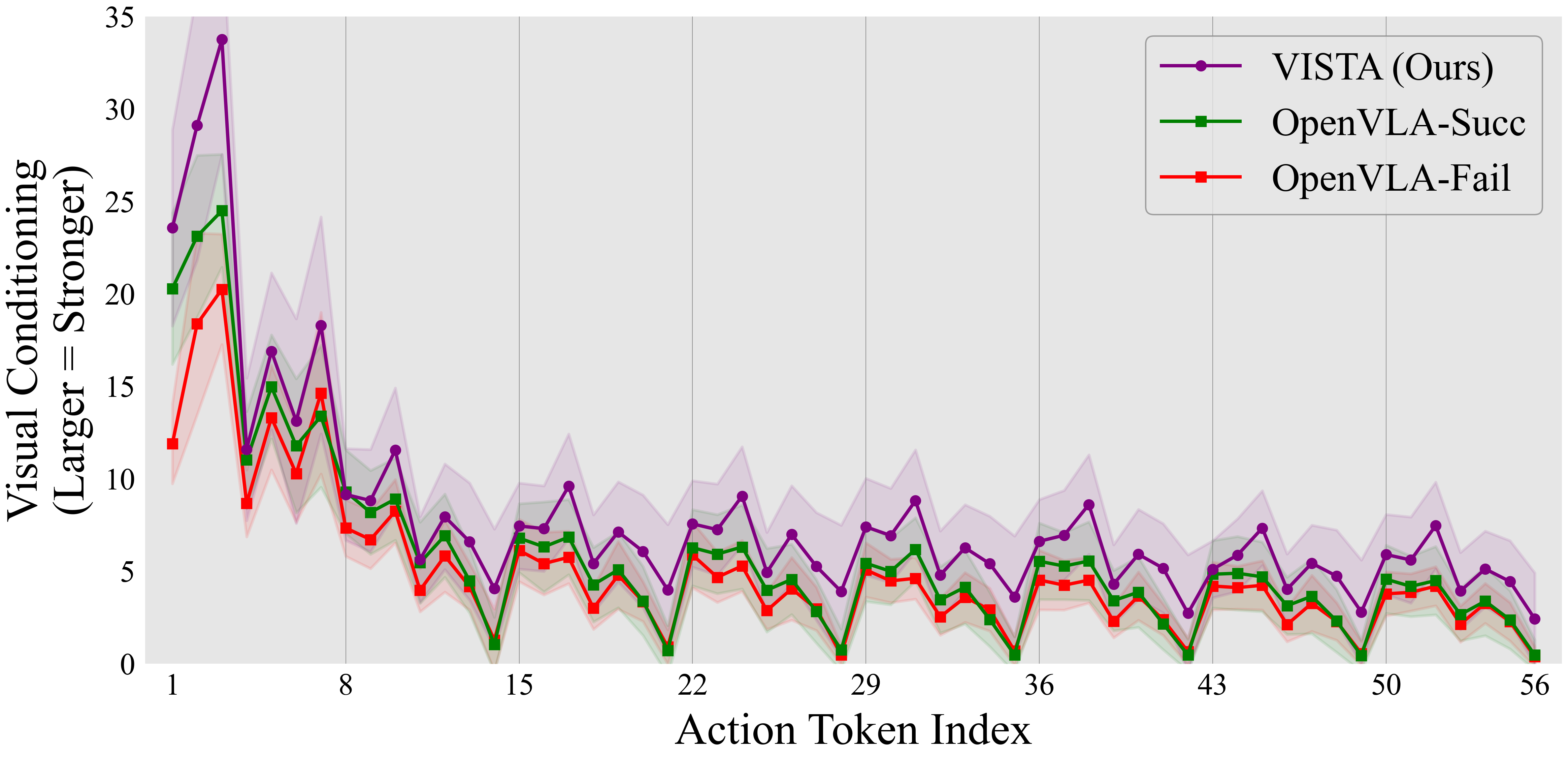
Token-level visual conditioning of 8-step OpenVLA and VISTA (Ours) in LIBERO-Spatial.
The vertical grids indicate that every 7 tokens decode to 1 action (56 tokens for 8 actions in total).
- We quantify VLA token-level visual conditioning as KL divergence between the action distributions conditioned on clean and perturbed visual inputs.
- We study baseline autoregressive OpenVLA and show that failed rollouts feature consistently weaker visual conditioning than successful rollouts.
- Our method (VISTA) enhances visual conditioning and improves task performance (see below)
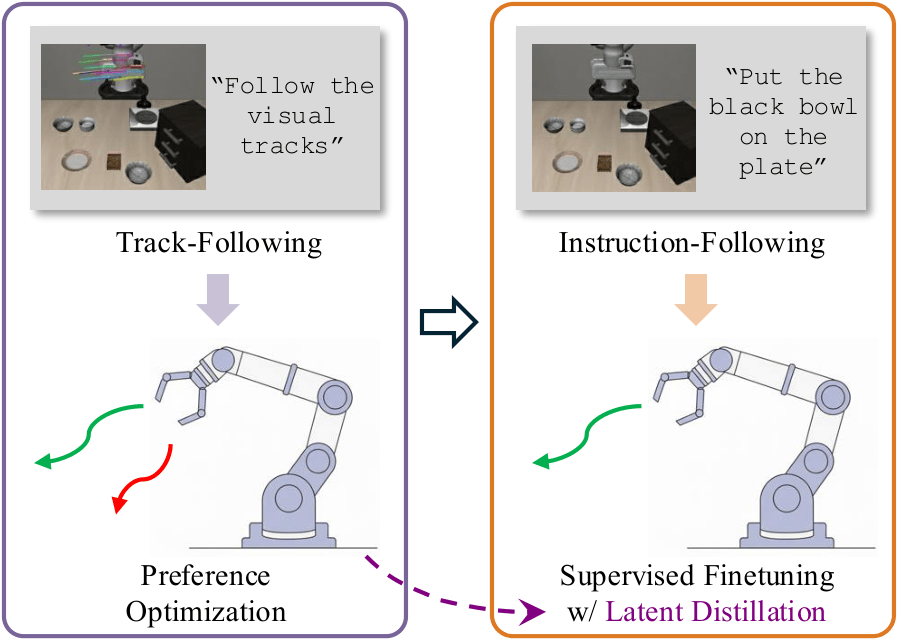
Method
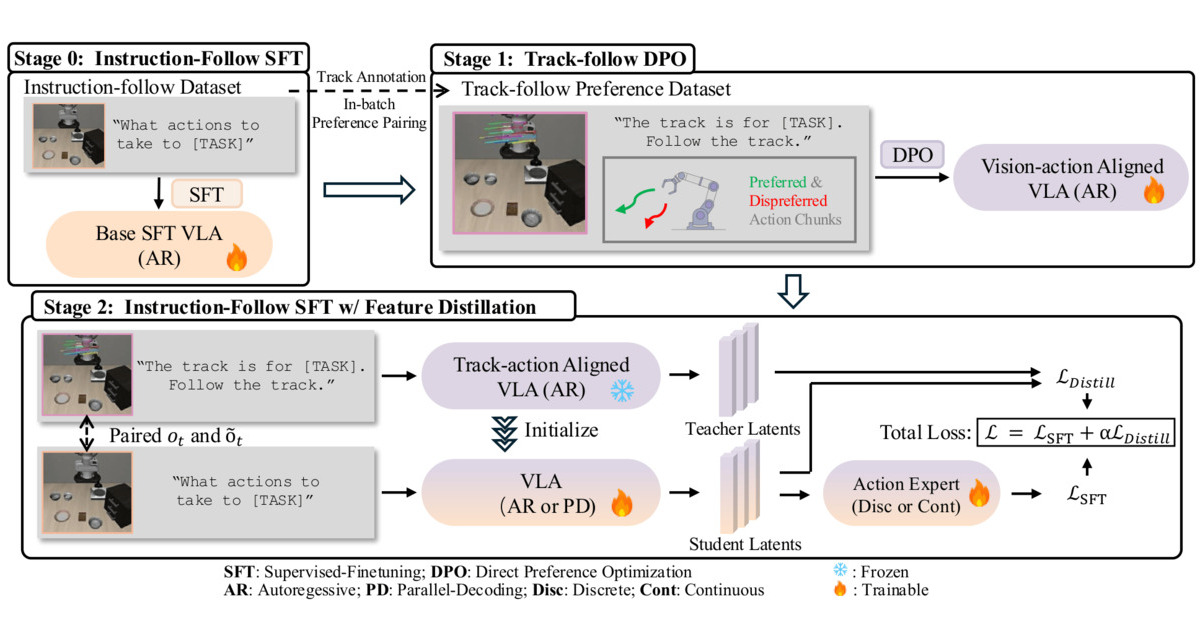
Illustration of VISTA training recipe.
- Regular instruction-following Supervised finetuning (SFT).
- Track-following Direct Preference Optimization (DPO) for aligning vision and action.
- Instruction-following SFT with latent distillation (cosine similary by default) from the aligned model.
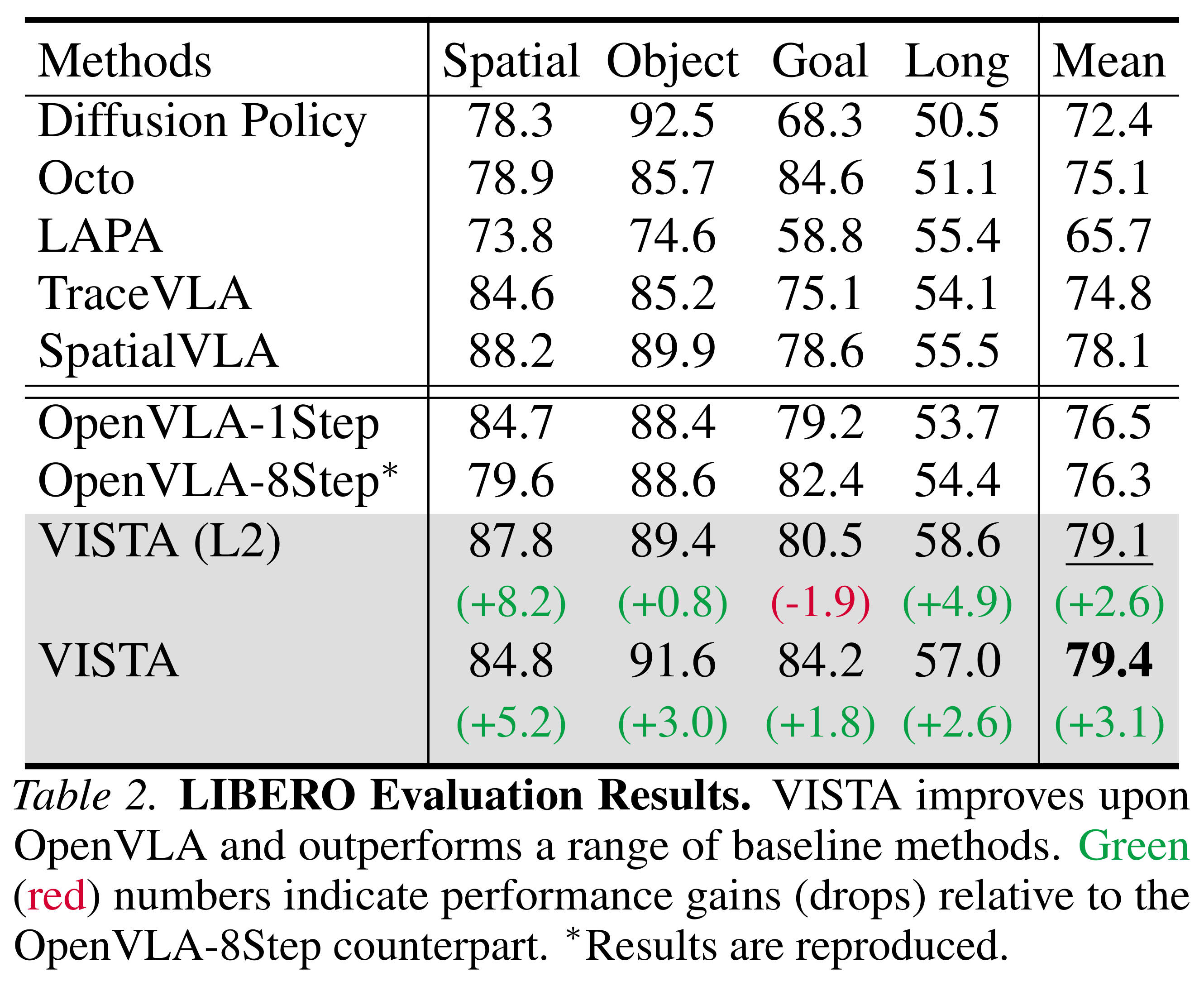
LIBERO Experimental Results and Demos
[Long 1] pick up the bbq sauce and place it in the basket
[Long 2] put both moka pots on the stove
[Spatial 1] pick up the black bowl on the ramekin and place it on the plate
[Spatial 2] pick up the black bowl on the wooden cabinet and place it on the plate
[Goal 1] push the plate to the front of the stove
[Goal 2] open the middle drawer of the cabinet
[Object 1] pick up the bbq sauce and place it in the basket
[Object 2] pick up the ketchup and place it in the basket
CALVIN Experimental Results and Demos
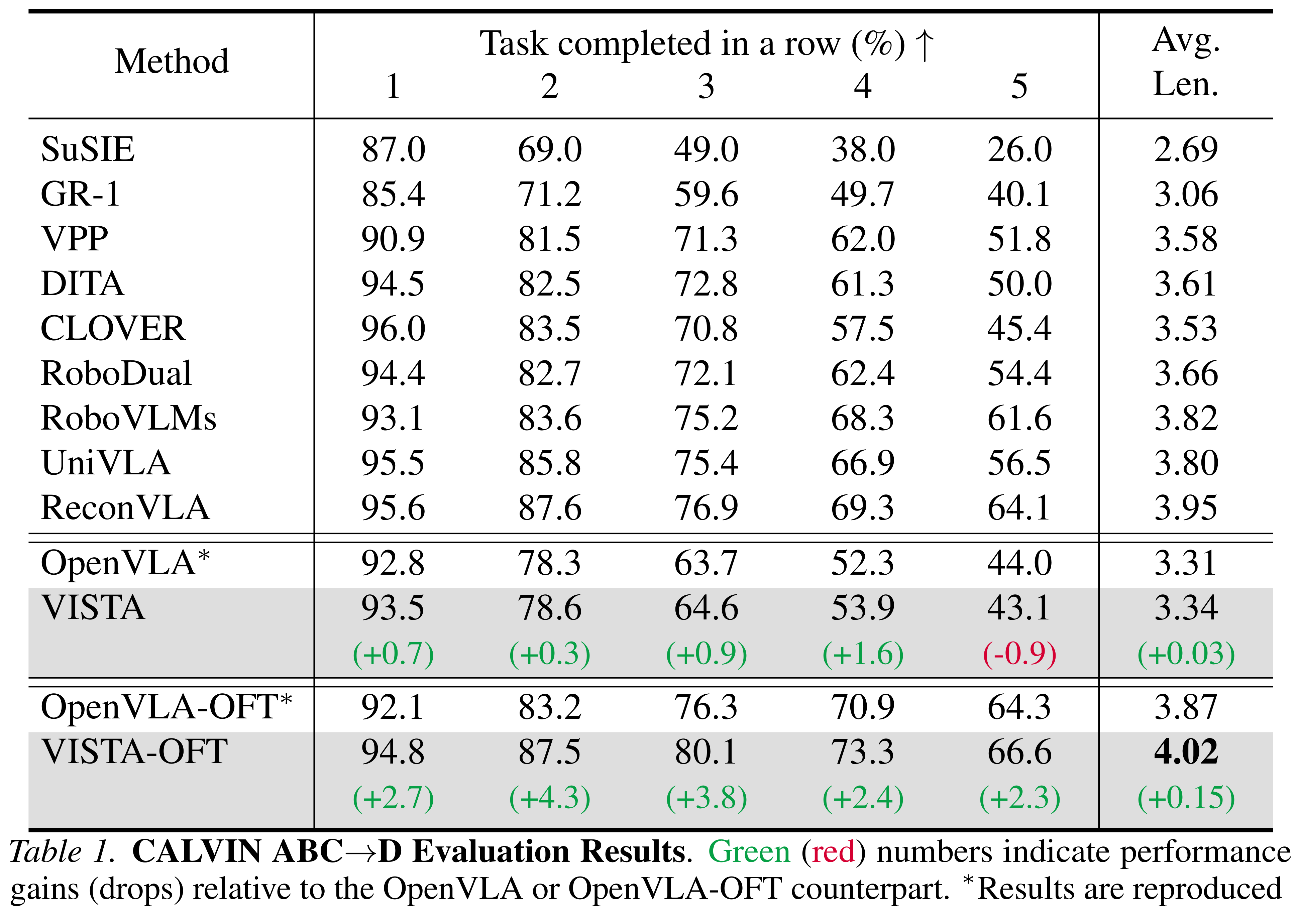

Demo 1

Demo 2

Demo 3

Demo 4

Demo 5

Demo 6
Analysis
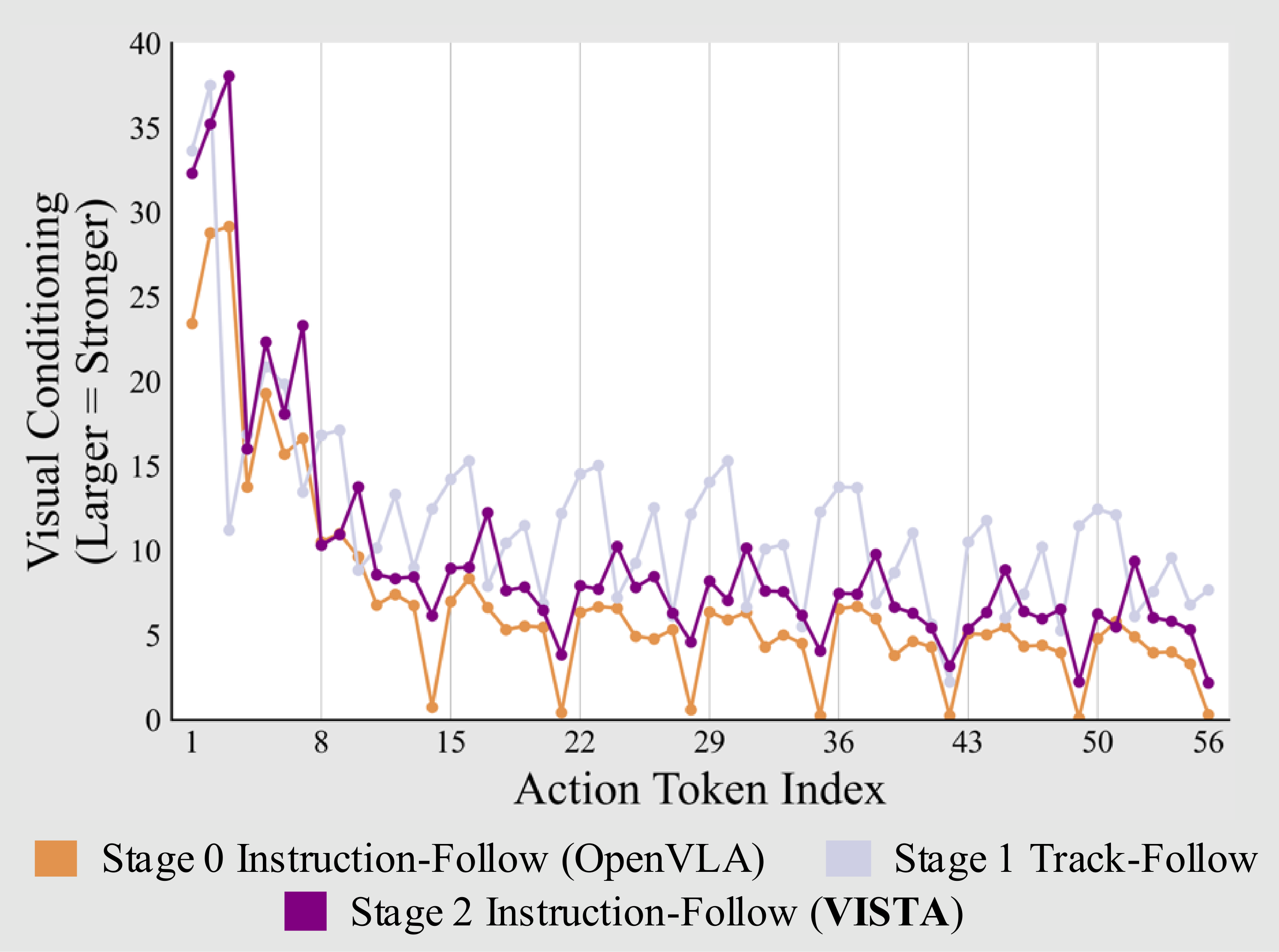
Visual Conditioning Across VISTA Training Stages.
Stage 2 with distillation transfers the enhanced visual conditioning to the instruction-following task compared with pure SFT in Stage 0.
BibTeX
@article{chen2026vista,
title={VISTA: Enhancing Visual Conditioning via Track-Following Preference Optimization in Vision-Language-Action Models},
author={Chen, Yiye and Jian, Yanan and Dong, Xiaoyi and Cao, Shuxin and Wu, Jing and Vela, Patricio and Lundell, Benjamin E. and Chen, Dongdong},
journal={arXiv preprint arXiv:2602.05049},
year={2026},
}